Aqui vou passar mais um exemplo de como utilizar CTEs - Common Table Expressions (Disponivel no SQLServer 2005 e 2008).
Nesse exemplo vou passar a dica de como somar o valor de uma coluna do registro atual com o registro anterior, como um subtotal.
Primeiro vou criar a tabela para os teste:
Create Table #tbValoresPagos (id int, dtPagamento DateTime, tpPagamento VarChar(1), vlPagamento Decimal(10,2))
E Inserir alguns valores de exemplos:
insert into #tbValoresPagos values(1, '2010-01-10 1:00', 'A', 125.30)
insert into #tbValoresPagos values(2, '2010-01-21 1:00', 'B', 15.00)
insert into #tbValoresPagos values(3, '2010-01-22 1:00', 'B', 1964.10)
insert into #tbValoresPagos values(4, '2010-03-20 2:00', 'C', 213.47)
insert into #tbValoresPagos values(5, '2010-03-20 2:30', 'A', 46.63)
insert into #tbValoresPagos values(6, '2010-04-01 3:00', 'B', 4899.21)
insert into #tbValoresPagos values(7, '2010-04-10 3:30', 'C', 3876.22)
insert into #tbValoresPagos values(8, '2010-05-01 3:40', 'C', 25.11)
insert into #tbValoresPagos values(9, '2010-05-05 3:40', 'B', 647.14)
insert into #tbValoresPagos values(10,'2010-05-05 4:40', 'B', 659.33)
insert into #tbValoresPagos values(12,'2010-05-12 5:40', 'C', 12.11)
insert into #tbValoresPagos values(13,'2010-05-20 5:42', 'A', 50.00)
insert into #tbValoresPagos values(14,'2010-06-20 5:45', 'A', 60.00)
/*
Por garantia, é melhor criar uma coluna Row_Number Particionado e Ordenado pelos critérios necessários antes de fazer a soma. Esta coluna Row_Number vai ser responsável pela identificação dos registros para sabermos qual é o atual e buscarmos o anterior.
A CTE cte_Recursivo seleciona o primeiro registro e juntamente com o Union All é utilizado a recursividade para que a segunda parte do Select traga sempre o registro atual + 1 (Próximo registro) respeitando os critérios utilizados no Inner Join.
*/
/*
Exemplo 1:
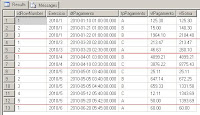
O exemplo abaixo é um mais simples, ele simplesmente soma a coluna vlPagamento registro a registro ordenado simplesmente pelo critério indicado no select da cte_ok, no caso o dtPagamento.
*/
;with cte_ok
as( select row_number() over (order by dtPagamento) as idRowNumber, dtPagamento, tpPagamento, vlPagamento
from #tbValoresPagos),
cte_Recursivo as
( Select idRowNumber, dtPagamento, tpPagamento, vlPagamento, vlPagamento as vlSoma
From cte_ok
Where idRowNumber = 1
Union All
Select A.idRowNumber, A.dtPagamento, A.tpPagamento, A.vlPagamento, Convert(Decimal(10,2), A.vlPagamento + B.vlSoma)
From cte_ok A
Inner Join cte_Recursivo B On A.idRowNumber = B.idRowNumber +1
)
Select * from cte_Recursivo
/*
Exemplo 2:
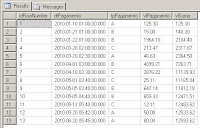
Agora o exemplo inclui um particionamento no Row_Number, o tpPagamento. Então o Row_Number é agrupado e reiniciado a cada tipo de tpPagamento diferente e ordenado por id.
Isso faz com que a soma da coluna vlPagamento seja reiniciado quando o tpPagamento mudar.
*/
;with cte_ok
as( select row_number() over (Partition by tpPagamento order by id) as idRowNumber, dtPagamento, tpPagamento, vlPagamento
from #tbValoresPagos),
cte_Recursivo as
( Select idRowNumber, dtPagamento, tpPagamento, vlPagamento, vlPagamento as vlSoma
From cte_ok
Where idRowNumber = 1
Union All
Select A.idRowNumber, A.dtPagamento, A.tpPagamento, A.vlPagamento, Convert(Decimal(10,2), A.vlPagamento + B.vlSoma)
From cte_ok A
Inner Join cte_Recursivo B On A.idRowNumber = B.idRowNumber +1
And A.tpPagamento = B.tpPagamento
)
Select *
from cte_Recursivo
Order by tpPagamento, idRowNumber

/*
Exemplo 3:
Um exemplo um pouco mais complexo inclui um particionamento de Ano/Mes no Row_Number. Então o Row_Number é agrupado e reiniciado a cada Mes/Ano e ordenado por id.
*/
;with cte_ok
as( select row_number() over (Partition by DatePart(year, dtPagamento), DatePart(Month, dtPagamento) order by id) as idRowNumber, Cast(DatePart(year, dtPagamento) as Varchar) + '/' + Cast(DatePart(Month, dtPagamento) as VarChar) Exercicio, dtPagamento, tpPagamento, vlPagamento
from #tbValoresPagos),
cte_Recursivo as
( Select idRowNumber, Exercicio, dtPagamento, tpPagamento, vlPagamento, vlPagamento as vlSoma
From cte_ok
Where idRowNumber = 1
Union All
Select A.idRowNumber, A.Exercicio, A.dtPagamento, A.tpPagamento, A.vlPagamento, Convert(Decimal(10,2), A.vlPagamento + B.vlSoma)
From cte_ok A
Inner Join cte_Recursivo B On A.idRowNumber = B.idRowNumber +1
And A.Exercicio = B.Exercicio
)
Select *
from cte_Recursivo
Order by Exercicio, idRowNumber